Success stories
Cette page (french) regroupe quelques projets accompagnés par GRICAD dans différentes disciplines et avec différentes problématiques.
Cette page (french) regroupe quelques projets accompagnés par GRICAD dans différentes disciplines et avec différentes problématiques.

La toute nouvelle machine de GRICAD
illustre le positionnement de l’unité dans un cadre
technologique avancé. Construite, installée, partagée
et mise en exploitation depuis décembre 2018 avec
le projet national Grid’5000, cette plate-forme,
intégrant les avancées techniques les plus récentes,
ouvrent des perspectives très intéressantes, tant pour
les communautés utilisatrices des technologies du
calcul et des données, que pour la communauté de la
recherche en informatique.
Pour la communauté du calcul scientifique, un
grand avantage pourra être tiré de l’infrastructure
de services fournie par le projet Grid’5000. Cette
dernière propose en effet des mécanismes très
efficaces de déploiement d’environnements systèmes
et applicatifs qui permettent de reconfigurer à la
demande les ressources de calcul afin de s’adapter
aux différents besoins des utilisateurs. Les chercheurs
de la communauté du calcul scientifique pourront
donc bénéficier de cette nouvelle fonctionnalité
pour importer leur propre environnement de calcul
(système d’exploitation particulier, configuration
légère et minimaliste, etc.) et ainsi s’affranchir des
contraintes inhérentes à un environnement de
production partagé, complexe et assez peu évolutif,
qui peut rendre difficile le déploiement de certains
environnements de calcul scientifique.
Grid’5000 offre aussi des outils d’introspection
très avancés sur les plates-formes (consommation
énergétique par exemple) qui permettront une
meilleure compréhension de l’usage qui est fait des
ressources de calcul et par là même, l’optimisation
de leur utilisation. Cet aspect est particulièrement
important dans le contexte du passage à l’exascale où
on s’attend à voir émerger des plates-formes de calcul
à l’architecture complexe (en termes d’hétérogénéité
et de hiérarchie des composants).
Pour la communauté d’utilisateurs Grid’5000, cette
plate-forme commune apporte un support de premier
plan pour l’étude des problématiques de calcul
scientifique. D’une part cette mise en commun permet
de construire une plate-forme de dimension bien
supérieure, primordiale pour les études de passage à
l’échelle des systèmes et des codes applicatifs. En effet
la validation expérimentale sur plusieurs milliers de
coeurs est aujourd’hui un prérequis pour prouver la
qualité des résultats de recherches dans le domaine
de l’informatique parallèle ou distribuée et donc
pour l’acceptation des publications associées dans de
grandes conférences comme SuperComputing.
Cette infrastructure innovante favorise les
collaborations fructueuses car transversales entre
les domaines scientifiques et facilite les transferts
de technologies : les uns apportent de nouveaux
problèmes et les autres de nouvelles techniques.
En collaboration avec le CHUGA et les
équipes des laboratoires du site dont les axes de
recherche touchent à la santé, GRICAD a participé
à la définition de l’architecture de l’Entrepôt de
Données de Santé (EDS) PREDIMED (Plateforme de Recueil et d’Exploitation de Données
bIoMEDicales). Concernant
l’exploitation de ces données, les ingénieurs de l’unité
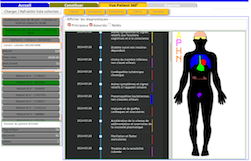
ont développé un outil de constitution de cohorte de
patients. Pour chaque patient, il est possible d’avoir
une vue graphique de son dossier, sous différents
angles : pathologies, prescriptions, parcours au sein
du CHU, ...
Le projet ERC F-IMAGE, porté par Michel
Campillo (laboratoire ISTERRE) vise à étudier
les applications en géophysique de l’intelligence
artificielle pour les risques naturels et les
géoressources. Il implique de nombreux partenaires,
en France et à l’étranger, et GRICAD participe
activement aux développements réalisés.
Les enjeux géophysiques sont importants : il s’agit
d’améliorer les connaissances des processus sismiques
et volcaniques pour atténuer les risques corrélés
causant des destructions massives tous les ans.
En sismologie et en géodésie, les données s’accumulent
rapidement, les informations fondamentales des
processus physiques de la terre sont contenues dans
ces données, mais les méthodes pour les extraire
sont à inventer. L’intelligence artificielle apparaît
comme la méthode qui réduira l’écart entre des grandes bases de
données d’observations disponibles et les possibilités de calcul
actuel.
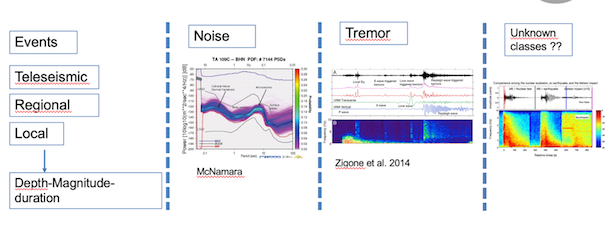
La détection de classes de signaux connus et
inconnus est au coeur du processus. Les catalogues
existants peuvent s’enrichir significativement en se basant sur l’apprentissage
supervisé appliqué aux données géophysiques et
géodésiques. La stratégie du projet est d’utiliser des
réseaux de neurones très profond et des algorithmes
de reconnaissances d’image déjà existant sur des
infrastructures de GRICAD (Multi-GPU NV100
32Go) permettant d’avoir des possibilités de plusieurs
dizaines de TFlops.
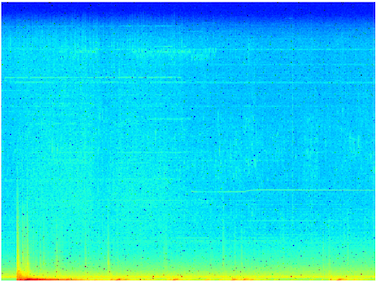
Le problème principal des signaux géophysiques
est la complexité spectrale ainsi qu’une dynamique
très forte. Dans le cadre de F-IMAGE, une approche
méthodologique novatrice a été adoptée sur
l’homogénéisation d’un dataset mondial (IRIS,
GEOSCOPE, IRIS) de 3600 canaux à 20sps et
des catalogues de signaux connus (séismes de
magnitudes différentes/profondeurs/azimuth,
trémors non-volcaniques, bruits océaniques etc..). Un
pré-traitement des données en spectrogrammes
normalisés et interpolés de fenêtres avec un ajout de
filtre S&P de taille fixe a été appliqué pour la création
d’une base de données d’images.
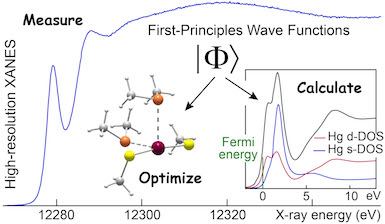
Le projet Mercurius (2,4 Mh entre 2016 et 2018)
piloté par A. Manceau (ISTerre) était consacré à
l’étude de l’impact du mercure sur les
écosystèmes terrestres et aquatiques ainsi que
sur la santé humaine.
L’enjeu était de
comprendre sous quelles formes chimiques et
structurales le mercure est immobilisé
durablement dans les géomatériaux, remobilisé
puis transféré dans les écosystèmes (sols,
sédiments, milieux aquatiques), puis bioaccumulé
et détoxifié par les organismes vivants
(plantes, animaux, homme). Grâce au
développement d’un spectromètre X à très haute
résolution spectrale et grande sensibilité
chimique (financé par le projet Equipex EcoX)
plusieurs formes organiques (méthylmercure) et
inorganiques du Mercure ont tout d’abord été
identifiées sur des supports naturels (cheveux,
plantes, moules, poissons, oiseaux).
Ensuite,
les moyens de calcul de GRICAD ont été mobilisés
pour modéliser, par le calcul thermodynamique et
cinétique des réactions chimiques des espèces
mercurielles, les configurations moléculaires
identifiées par spectroscopie.
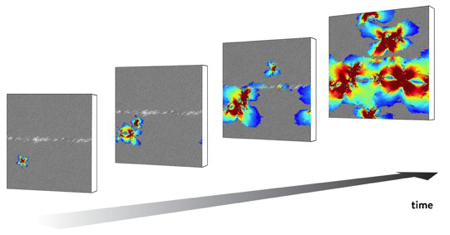
Le projet GLASSDEF (6,9 Mh), financé par une bourse "advanced" de 1,8 M€ du European Research Council et piloté par J.-L. Barrat (LIPhy) avait pour but de développer des modèles microscopiques de la déformation de solides désordonnés: ces solides, qu'il s'agisse de systèmes mous tels que les gels où les mousses ou de systèmes beaucoup plus durs tels que les verres métalliques, peuvent s'écouler comme des liquides si les contraintes appliquées sont suffisantes. Au niveau microscopique, les mécanismes d'écoulement sont cependant très différents de ceux des liquides: ils impliquent des instabilités locales du solide appelées zones de cisaillement, assimilables à des microfractures, qui interagissent entre elles et donnent lieu à un comportement collectif impliquant des événements de toutes tailles, distribués suivant des lois de puissance analogues à la loi de Gutenberg Richter bien connue en sismologie. Les travaux numériques réalisés sur le calculateur parallèle Froggy, et en particulier sur ses unités de processeurs graphiques (GPU) ont permis de caractériser en détail cette dynamique collective à l'origine de la déformation, et d'en faire émerger les lois statistiques qui peuvent être comparées aux résultats expérimentaux ou aux modèles théoriques.
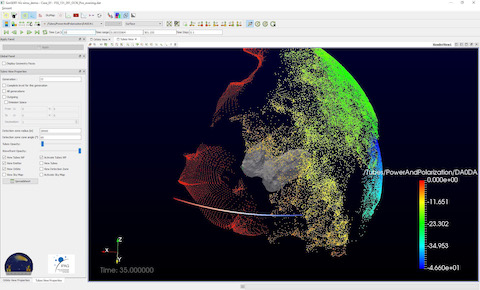
CONSERT (COmet Nucleus Sounding Experiment by
Radiowave Transmission) est un instrument radar
à bord de la sonde Rosetta et de son
atterrisseur Philae. Il a sondé l'intérieur de
la comète 67P/Churyumov-Gerasimenko en Novembre
2014. Ces mesures ont permis de contraindre les
propriétés physiques des matériaux en présence
en profondeur dans le noyau cométaire :
porosité, composition en termes de poussières et
de glaces. L'instrument mesure fondamentalement
le temps de propagation d'une onde radio à
travers un milieu diélectrique. Des simulations
numériques (projet SimSERT, 1.4 Mh, 2014-2019,
Y. Rogez, IPAG) réalisées sur les moyens de
calcul CIMENT ont permis dans un premier temps
de réaliser la planification des opérations
spatiales de l'instrument CONSERT, en anticipant
les configurations de mesures possibles; à la
fois pour fournir les contraintes radar pour la
sélection du site d'atterrissage de Philae et
pour les définitions de trajectoires de
Rosetta. Une fois les mesures effectuées, les
simulations numériques ont permis de contraindre
les valeurs possibles de permittivité
diélectrique du matériau cométaire, ce qui
constitue une entrée essentielle dans l'analyse
de sa composition.
AURAGEN est un projet s’inscrivant dans le soin, financé par la DGOS (Direction Générale de l’Offre de Soins), dans le cadre du Plan France Médecine Génomique 2025. L’objectif de ce projet est la création d’un laboratoire de biologie médicale multi-site dédié à la médecine génomique. La mise en place des analyses bioinformatiques des données de séquençage pan-génomique pour les maladies rares est réalisée à Grenoble en utilisant les ressources de l’UAR GRICAD. Ainsi, l’UAR GRICAD permet de disposer d’un environnement de recherche et développement en amont de la mise en pré-production des procédures d’analyses sur l’infrastructure dédiée au projet AURAGEN.

Qu'il s'agisse d'expérimentation ou d'observation écologique des
pratiques sociales du Web ou des réseaux sociaux, la collection et
l'exploitation de traces numériques ou de flux massifs de données font
désormais partie de l'outillage des sciences sociales. De plus en plus
de projets interdisciplinaires à l'initiative de laboratoire de
sciences sociales proposent un volet empirique guidé par les
données. Il s'agit le plus souvent d'innovations dans la manière
d'aborder un terrain et d'instrumenter son exploration qui appelent
non seulement de nouvelles techniques mais également de nouvelles
méthodes de production et d'analyse des observables. La participation
de GRICAD à divers initiatives de ce type, permet d'apporter un
soutien à l'innovation technique aux chercheurs dans l'ingénierie de
la donnée et du big data, mais aussi de capitaliser l'expérience entre
les projets au bénéfice des communautés scientifiques.
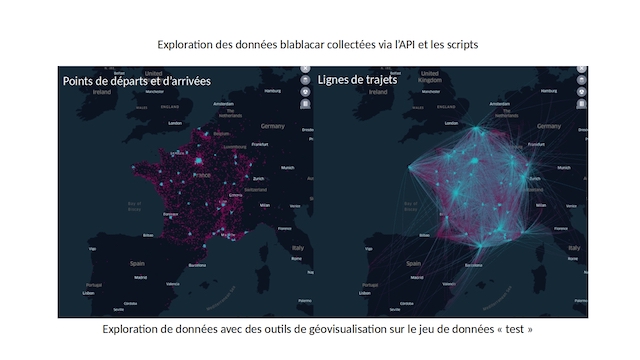
L'étude sur les mobilités inter-urbaines menée
par les chercheurs du laboratoire de PACTE dans
le contexte du DataInstitute, en collaboration
avec la plateforme BlablaCar illustre ces
nouvelles possibilités scientifiques impliquant
la collecte de très gros jeux de données. Cette
étude en cours, préfigure le programme de
recherche MobilAir (projet Idex UGA), dans
lequel de très grosses collections de données
multidimensionnelles sont envisagées, mixant des
relevés GPS (mobilité), des données
d'accélérométrie (activité physique et
mobilité), des carnets de bords (mobilité et
économie), des enquêtes (activité physique et
psycho), etc.
Le Laboratoire d’Ecologie Alpine effectue des
recherches visant à comprendre l’origine de la
biodiversité, son rôle dans le fonctionnement
des écosystèmes et la réalisation des activités
humaines, et de prédire son évolution dans un
contexte de changement climatique. Ses
chercheurs produisent et utilisent de très gros
jeux de données (prospections de la
biodiversité, imagerie satellitaire, génomiques
haut-débit, etc..) et déploient une activité
modélisation intense, qui nécessitent
d’importants moyens de stockage et de
calculs. Plusieur projets en particulier sont de
gros utilisateurs des moyens fournis par l’UAR
GRICAD.
Le projet TEEMBIO, porté par une ERC entre 2012 et 2016 et depuis par
plusieurs ANRs, vise à comprendre et modéliser
la structure et la distribution de la
biodiversité. Pour ce faire, les chercheurs
utilisent des données de biodiversité de
l’échelle globale à locale qui proviennent soit
de base de données existantes, soit de données
collectées par nous même, et les analysent en
fonction de paramètres physiques ou
biologiques. Les modèles utilisés sont variés,
de type machine learning, GLM, et requièrent le
plus souvent du déploiement massif (jobs
séquentiels), ou des runs gourmands en mémoire
vive. Les chercheurs ont ainsi pu montrer qu’une
augmentation de 5% des aires protégées mondiales
doublerait la protection de l'ensemble des
vertébrés terrestres (Pollock, Thuiller & Jetz
2017 Nature).



